五笔字型输入法以其高录入速度及低重码率等优点,得到了广大电脑用户的青睐,随着时代的发展,学会五笔字型不再是少数电脑高手的专利,而成为人人必备的基本技能。本章将介绍使用五笔字型输入法输入汉字。
一 体验五笔字型输入法
“五笔字型输入法”究竟是怎样的一种输入法呢? 也许你认为这是一个不重要的问题,但是仔细想一下,如果连这个简单问题都不知道,又谈何学好五笔字型输入法呢?
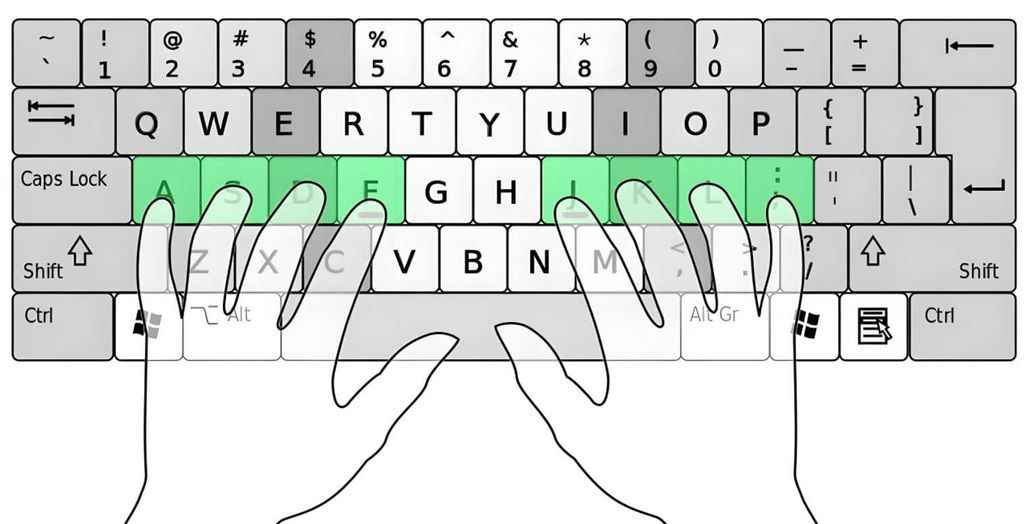
现在就让我们实际来体验一下用“五笔字型输入法”输入汉字的过程:首先启动Word文字处理软件,在可录入情况下,将输入状态调整到“五笔字型输入法”。接着按顺序敲键盘“R”“A”“E”“T”,就可以输入一个“撒”字到屏幕上。其中字母“RAET”英文字母序列就称为“撒”字的编码。
“五笔字型输入法”是怎样输入“撒”字的呢?如下图所示,表示了“撒”字的取码过程。现在明白了吧,原来五笔字型认为“撒”字是由“扌”、“”、“月”、“攵”这四个“零件”(五笔字型输入法称“字根”)组合而成的。由下图可知,“扌”这个“零件”在键盘上分布在“R”键上、“”分布在“A”键上、“月”分布在“E”键上、“攵”分布在“T”键,所以“撒”字的编码就是“RAET”。
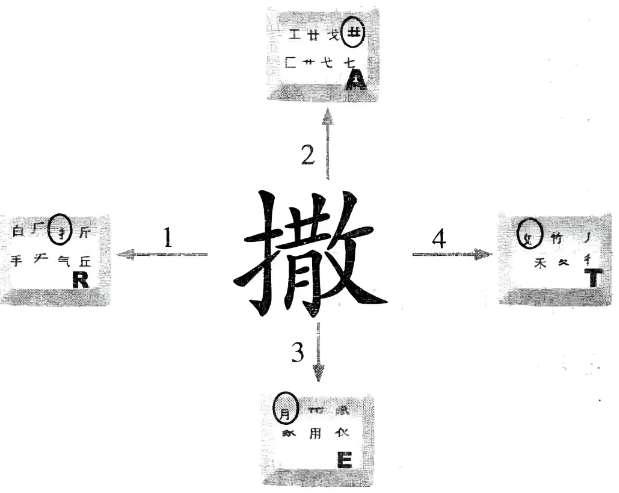
也许你要问,为什么编码是“RAET”而不是“RETA”或者“EATR”呢?这是因为五笔字型汉字输入法在拆分汉字的时候,要按照一定的顺序来进行,而不是想按什么顺序拆分就按什么顺序拆分。
输入字根的顺序:一般按照书写顺序,即先左后右,先上后下,先外后内。例如:
做:亻、十、口、攵
落:艹、氵、夂、口
困:囗、木
但是有几种特殊情况需要注意:
(1)“达、这”等有走之旁“”的汉字,输入字根顺序为:先输入“辶”内的字根,最后输入“辶”字根。

(2)“赵、旭、起、匝、国”等半包围或全包围结构的汉字,严格按照从左到右、从上到下、包围到被包围的顺序输入字根的编码。

(3)“抛”字等中间字根为“九”的汉字输入顺序。
(4)“涟”字等中间字根为“”的输入顺序。

二 五笔字型输入法打字步骤
现在你已经知道了,五笔字型输入法根据组字原理把汉字拆分成一个一个基本字根,并把它们按一定的规律分别排列在25个字母键上(z键除外)。在录入汉字时,首先将汉字拆分成一个一个单独的字根,然后再按书写顺序依次按下键盘上与字根相对应的键,系统会根据输入字根组成的代码,在五笔字型输入法的编码库中检索出你要打的字。
所以要在电脑上用五笔字型输入法打字,必须按照下面的操作步骤来进行:
- 将汉字分成一个一个独立的“零件”(字根)。需要注意的是,一定要保证拆分出来的每一个零件都是基本字根,否则就是错误的拆分方法。
- 找每个“零件”(字根)在键盘上的键位位置。
- 再按书写顺序输入每个键的编码,就完成了打字的过程。 例:照
- 第一步:将“照”拆分成一个一个单独的“零件”(字根)。

第二步:找每一个“零件”(字根)在键盘上的位置(五笔字型输入法有一个字根表,列出了每一个键上分布了哪些字根)。
第三步:在五笔字型输入法状态下,按顺序敲入“JVKO”键可以看到我们已经把“照”字输入到屏幕上了。

三 顺口溜记字根
字根,就是组成汉字的零件。五笔字型(86版)共设计了130多种字根,按照一定的规律排列在25个键位上(z键除外),如下图。我们在每个键位上字母前都标记了一个数字。如A键上的15,J键上的22,通过这个数字,我们人为的把键盘划分了五个区。其中标记11-15的键位为一区:标记21-25的键位为二区:标记31-35的键位为三区,以此类推。
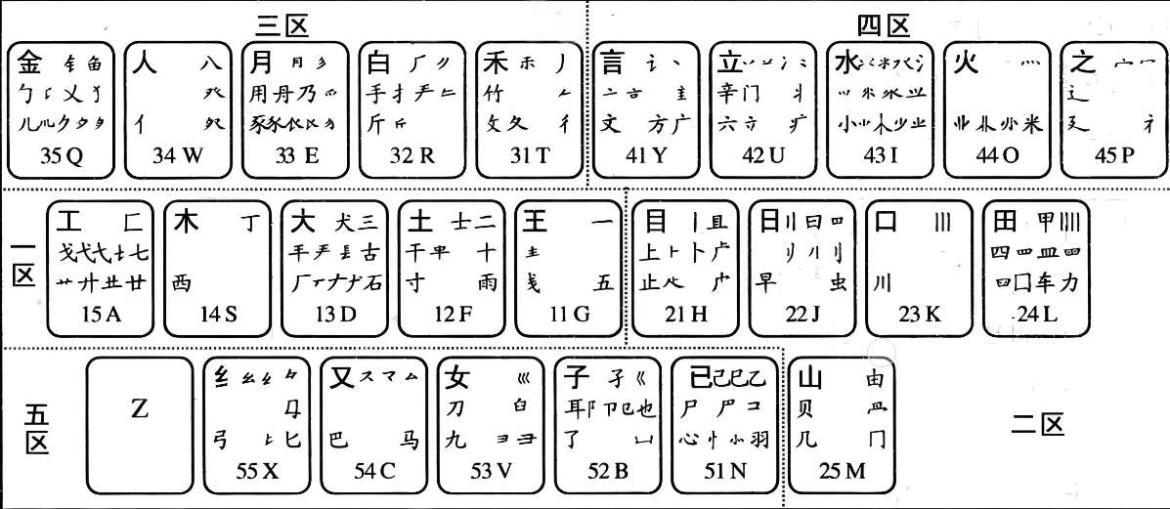
五笔字型的难点是什么?五笔字型的精髓在哪里?对一个熟悉五笔字型的人会一口回答出答案:字根。 的确,许多人不愿意或是害怕学习五笔字型输入法,实际上就是害怕背诵众多的字根。
学习字根时,需要把下面五首顺口溜朗诵几次。记住,你不必理解每句话是什么意思,只需要按序号分区朗读,把每一个区当作一首诗,要尽量找到读古诗的感觉,当然读得越熟就会在以后的学习中越轻松。

背顺口溜的目的是为了让你在背顺口溜的同时学会字根。因此,必须要知道每句顺口溜里面包含的字根信息。换句话说,也就是要从顺口溜里面找字根。下面我们就分区来讲解顺口溜。
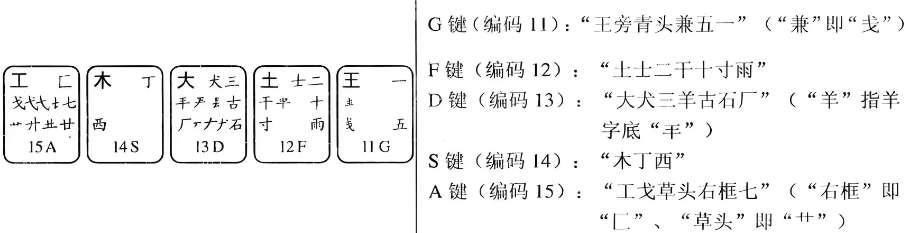
3.1 第1区字根
3.2 第2区字根

3.3 第3区字根
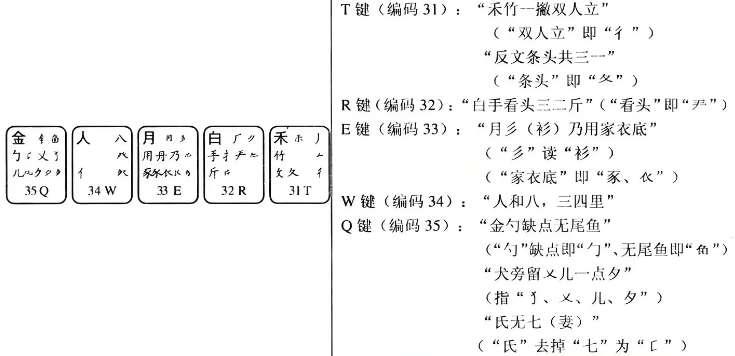
3.4 第4区字根
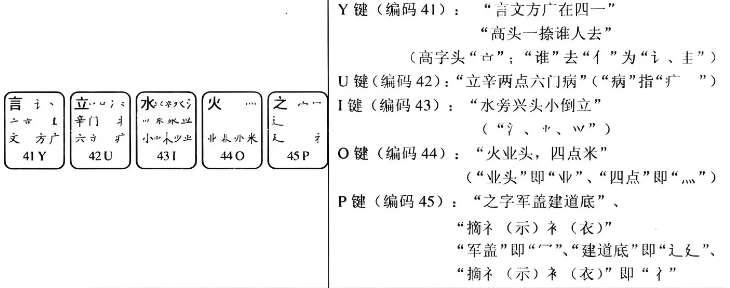
3.5 第5区字根
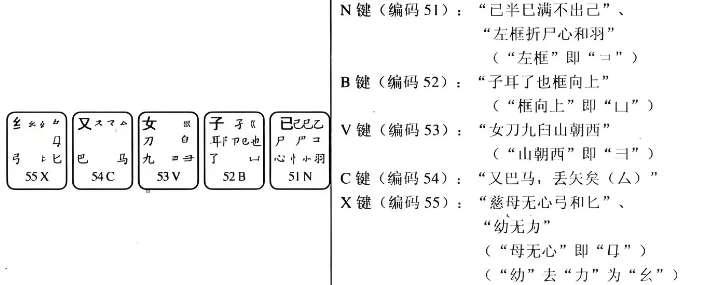
上面对顺口溜中一些不易理解的部分进行了讲解,剩余其他的字根大致上与顺口溜能够搭配一致。
四 将汉字拆分成字根
现在我们已经知道了打字的步骤,也明白了其中最重要的一步就是将汉字拆分成字根。但是究竟如何拆分字根?对于有多种拆分方法的汉字我们应该如何处理呢?
我们通过举例来说明这个问题: “林”字怎么拆分?观察它的字形可以看出,它有两个独立的部分“木”,所以很容易拆分成“木、木”两个字根,这也合乎人们的习惯。
林=木、木
但是并不是所有的汉字字形都与“林”字一样简单易拆,比如说有些汉字可以有很多种拆法,如:
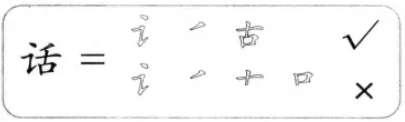
“话”字就有两种拆法,而且每一种拆法都保证了拆出来的“零件”是单独存在的字根。也就是说,拆分没有错,这个时候怎么取舍呢?
俗话说“没有规矩,不成方圆”,五笔字型汉字输入法的设计者为了解决这个问题,规定了几种原则,只要我们在拆分汉字时严格按照这个原则,对于一字有多种拆法的问题就会迎刃而解了。
五笔字型输入法拆分汉字原则:
4.1 “取大优先”原则
这个原则指导你在拆分汉字时,按书写顺序拆分出尽可能大的字根,保证拆分出的字根数量最少。
例如上例中的“话”字,我们现在有了这个原则,就可以轻松判定将它拆分成“讠+)+古”是正确的,因为它拆分出的字根数量是最少的。
下面这几个例子可以帮助你理解“取大优先”原则:

4.2 “能连不交”原则
顾名思义就是指能够拆分成相连接的字根就不拆分成互相交叉的字根。
例如“天”字既可以拆分成“一、大”,又可以拆分成“二、人”。如果拆分成“一、大”,两个字根就是相连的:如果拆分成“二、人”,两个字根就是相交的。根据“能连不交”的原则,很显然我们要把它拆分成“一、大”。

4.3 “能散不连”原则
这个原则指的是如果两个字根既可以拆分成散的结构,又可以拆分成连的结构,我们就要把它统一拆分成“散”的结构。

很显然,上面例子中的“羊”字拆分成“羊”两个字根是正确的。因为这种拆法两个字根之间的结构是散,而另外一种拆法字根之间的关系是相连。另外,从“取大优先”原则我们也可以知道第一种拆法是正确的,因为它保证了拆分出来的字根数量最少。由此看来,这几种原则应该互相配合灵活使用,才能达到一步拆分正确的目的。
4.4 “兼顾直观”原则
“兼顾直观”原则和“取大优先”原则是相通的,规定在拆分时笔划不能重复或是截断,尽量符合一般人的直观感受。通俗一点的讲就是要使每一个拆分出来的字根看起来不别扭。

且”字拆分成“月+一”看起来比拆分成“门+三”要直观一些。总之,“兼顾直观”原则讲究的是视觉感受。力求拆分出的字根自然、大方。
现在你已经具备拆分汉字的基础知识了。一般来说,只要掌握了上面这四种汉字拆分原则,并且将理论联系实践,不断揣摸,就能够做到快速、准确地拆分出每一个汉字。
4.5 四码单字录入
有些字,刚好能拆分成四个字根,如:念。
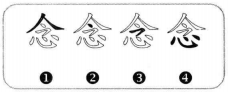
规则:按书写顺序从左到右,从上到下,从外到内输入四个字根的编码。
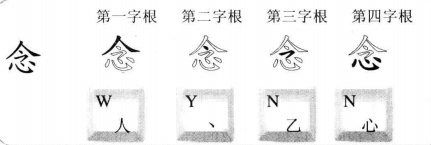
也许你要问:为什么可以把“念”字拆分成“人、、、乙、心”,四个部分。而不可以把它拆分成“今、心”两个部分呢?这是因为组成汉字的基本单位是字根,“人、、、乙、心”都是基本字根,而“今”不是基本字根,所以不能拆分成“今、心”。我们在拆分每一个汉字的时候都要遵循这个原则,保证拆分出来的每一个部分都是一个单独的字根。
为了让你对刚好四个字根汉字的录入规则有更深层次的了解,我们现在再列举几个刚好四码汉字的录入方法。
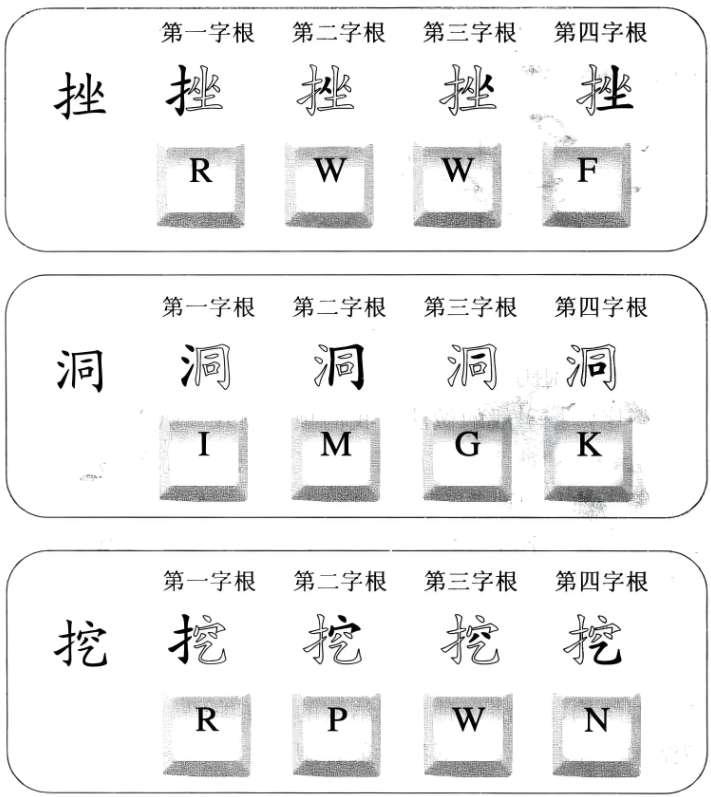
4.6 不足四码单字录入
在学习不足四码单字的录入前,我们首先要学习重码与识别码。
4.6.1 重码与识别码
- 重码概念
顾名思义,重码就是相同的码,如果两个或几个汉字的编码相同,我们就说它们重码。 如“对”与“圣”的编码都为“CF”,那它们就是重码字。单字不足四码常容易构成重码。
重码出现的几种情况 相同字根按不同顺序组合,构成重码,如同样是“口、八”两个字根,可组成“只”也可组成“叭”字。字根不同时,也有可能出现重码,如“付”是由“亻、寸”组成,而“仕”是由“亻、士”组成,但他们的编码却都是WF。
识别码的概念 我们从一个例子开始了解识别码。如果我们想输入“叭”字,按一般的做法,我们顺次输入“叭”字两个字根“口、八”的编码“KW”,但是却不会出现“叭”字,而是出现了“只”字。因为这两个字是重码字,所以计算机并不知道我们输入的是“叭”字还是“只”字。我们要打出“叭”字,必须再加打一个编码,使“只”字与“叭”字区别开来。现在我们输入编码“KWY”,“叭”字就已经被打出来了,最后输入的编码“Y”就是识别码。
如何确定识别码
- 第一步:看汉字的字型结构,认清每种字型结构的数字编码。汉字共有3种字型结构:左右型,上下型,杂合型。

- 第二步:看末字根的末笔画,认清每种末笔画的数字编码。 末笔画一般有5种形式,如表所示。

- 第三步:根据汉字的末笔画末字根和字型结构分析识别码。
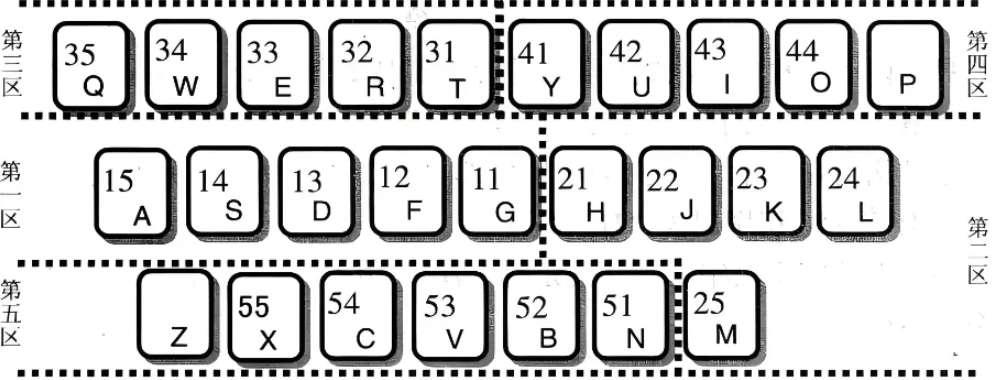
我们用数字来表示交叉识别码。交叉识别码=末笔划编码+字型编码
上面式子中的“+”是“连接”的意思。还是用一个例子来说吧,例如“杜”字,末笔划为横“一”,对照表可知,数字编码为“1”:字型结构为左右型,数字编码为“1”,因此它的识别码为1+1即“11”,“11”就是数字形式的交叉识别码。从键盘上可以知道,11对应的等价的英文字母是“G”,所以“倍”字的交叉识别码为“G”。数字与字母在键盘上的对应关系如图所示:
为了更好的了解识别码的组成规则及如何确定一个汉字的识别码,下面以表格的形式列出了识别码,以便查询。

每个单独的项后面跟的数字表示它的数字编码。如在第二行中,“横”后跟一个数字1,表示末笔为横“一”的数字编码为1。每个字母前面的数字表示数字识别码,它是一个两位数字,个位表示汉字的字型编码,十位表示汉字的末笔编码。如“R”键前面的数字为“32”,即表示它的末笔编码为“3”,字型编码为“2”。
4.6.2 识别码举例
- 拆分成两个字根的汉字加打识别码
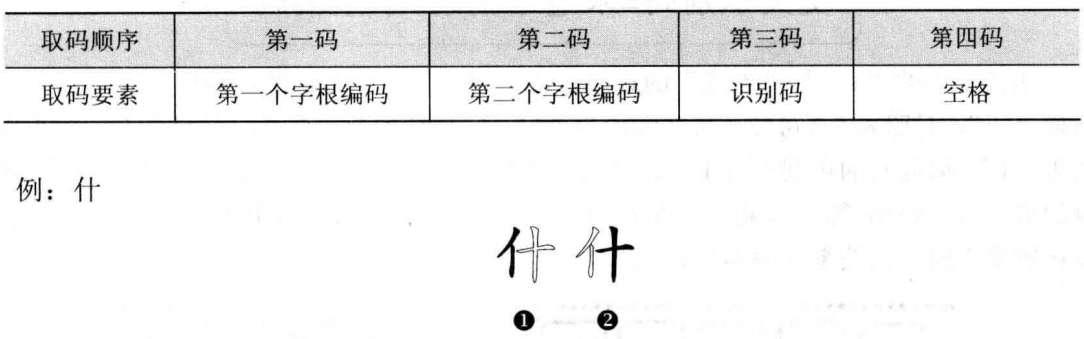
“什”字只有两个字根,依次输入第一个字根编码、第二个字根编码,然后再输入识别码,最后输入空格。“什”字的末字根是“十”,“十”的末笔画是竖“|”,数字编码为“2”; “什”字的字型结构为左右型,数字编码为“1”,“什”字的数字识别码为21,对应的键位是“H”,所以“什”字的识别码为“H”。 除开简码外,五笔字型汉字输入法规定每个汉字的编码都需要四位,如果不足四位编码的则补充一个空格键。
- 拆分成三个字根的汉字加打识别码

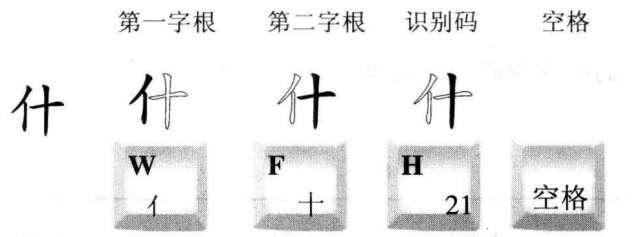
“做”字的末字根为“攵”,“攵”的末笔画为“、”其数字编码为“4”;“做”字的字型结构为“左右型”,其数字编码为“1”,所以其数字识别码为41,对应的键位是“Y”,字的识别码为“Y”。
4.6.3 关于末笔的特殊规定
- 对“辶、廴”做偏旁的字和全包围字(如:国、因),它们的末笔规定为被包围部分的末笔。
小提示: 如果用“辶”包围一个字根组成的部分位于另一个字根后面,所得到的字根末笔为“辶”字的末笔“、”。比如“链”字的末笔画为“辶”的末笔画“、”。

- 对“九、力、七、刀、匕”等字根,当它们参与“识别码”时一律用“折笔”作为末笔。

对“咸、我、浅、成、茂”等相似形状的字,取末笔为“)”
有些字单独带一个点,比如“刃、叉、头、太”等字,规定把“点”当作末笔。


4.7 超过四码单字录入
规则:对于超过四个字根的汉字,我们选取它的第一、第二、第三和最末字根组成四位编码。 如“撵”字共有六个字根。
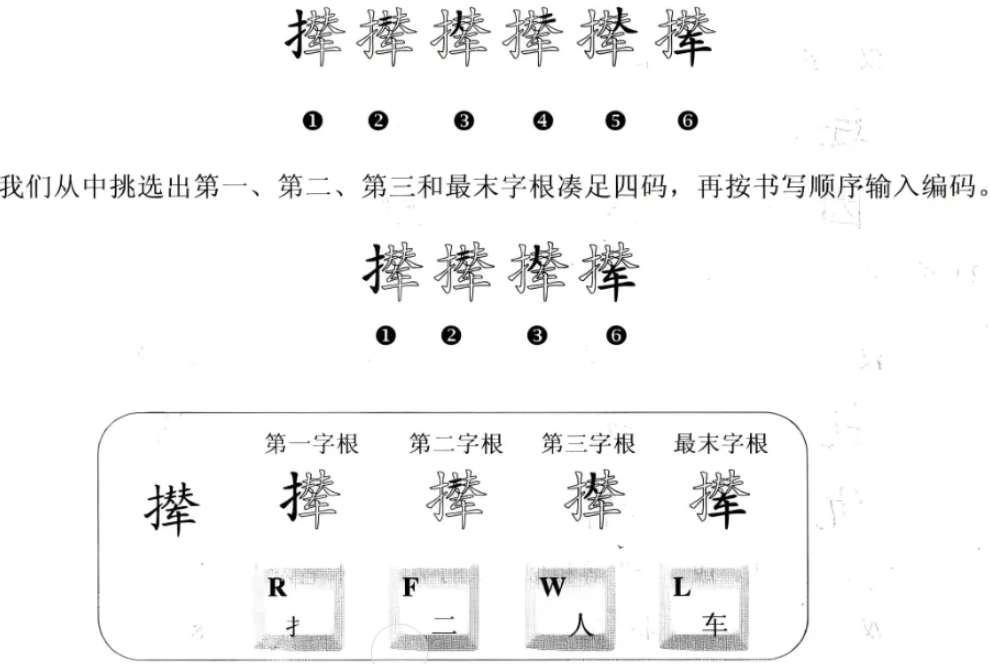
超过四个字根组成的汉字取码时的规则与前面的内容有一点不同,它最后一码要求取这个字的最末字根,所以在拆分这类汉字的时候,弄清汉字的最末一个字根是非常重要的。下面再举两个例子来说明这个问题,请注意每个汉字的取码规则。
4.8 键面字的录入
在不足四个字根组成的汉字中,有一种是由一个字根组成的特殊汉字。我们称这类汉字为“键面字”。“键面字”又分为两类:键名汉字与成字根汉字。
4.8.1 键名汉字的录入
把一个键连敲四下,打出来的字就是键名汉字。观察字根表我们可以发现键名字排在字根的第一个位置。 五笔共有25个键名字,在键盘上分布如图所示。

键名汉字的录入规则:把所在键连敲四下,即可打出键名汉字。例如:
- 敲“WWWW”得到“人”字。
- 敲“VVVV”得到“女”字。
- 敲“HHHH”得到“目”字。
4.8.2 成字根汉字录入
在键盘上,除了键名汉字外,本身既是字根,又是汉字的字根,就称为成字字根。成字根汉字录入规则:

“干”字的编码即为:FGGH
小提示: 如果成字根的总共取码不足四码,按顺序输入完编码敲空格键即可。如成字根汉字的总共编码超过四码,则取码为:报键名+首笔画+次笔画+末笔画。
4.9 简码汉字的录入
简码就是简化了的编码,所以我们在打简码的时候不需要按照前面的录入步骤来录入,我们采用一种更加容易,更加简单的方式来录入它们。 简码汉字共有三类,分别为一级简码、二级简码、三级简码,本节先来学习一级简码。
4.9.1 一级简码
一级简码共有25个,在键盘上的分布情况如图所示。

录入规则:简码所在键+空格。例:
- “我”字的编码即为“Q+空格”。
- “人”字的编码为“W+空格”。
- “有”字的编码“E+空格”。 由于在键盘上看一级简码很费力,所以我们将它单独列出来,可以把它当一首古诗来朗读,当到了基本能记住的程度,就应看着表的右半部分或者键盘把每个一级简码同键位直接联系起来。

4.9.2 二级简码
二级简码一共有600多个。录入规则:第一个字根+第二个字根+空格 例:阿

“阿”字的编码即是“B+S+空格”
小提示: 当然,你也可以输入完“阿”字的编码 “B+S+K+空格”来达到输入的目的,而不用简码输入。但是这样会减慢打字的速度,所以在实际的汉字录入中要尽可能的用简码输入。
要用二级简码输入,你必须知道哪些字是二级简码,这就需要你多多的练习二级简码,达到熟能生巧的程度。下面以表格的形式列出了所有的二级简码,每个汉字的编码等于行编码+列编码。如“于”字的编码为“G+F”、“理”字的编码为“G+K”。表格中有些地方是空格,则表示这个编码的二级简码字不存在。
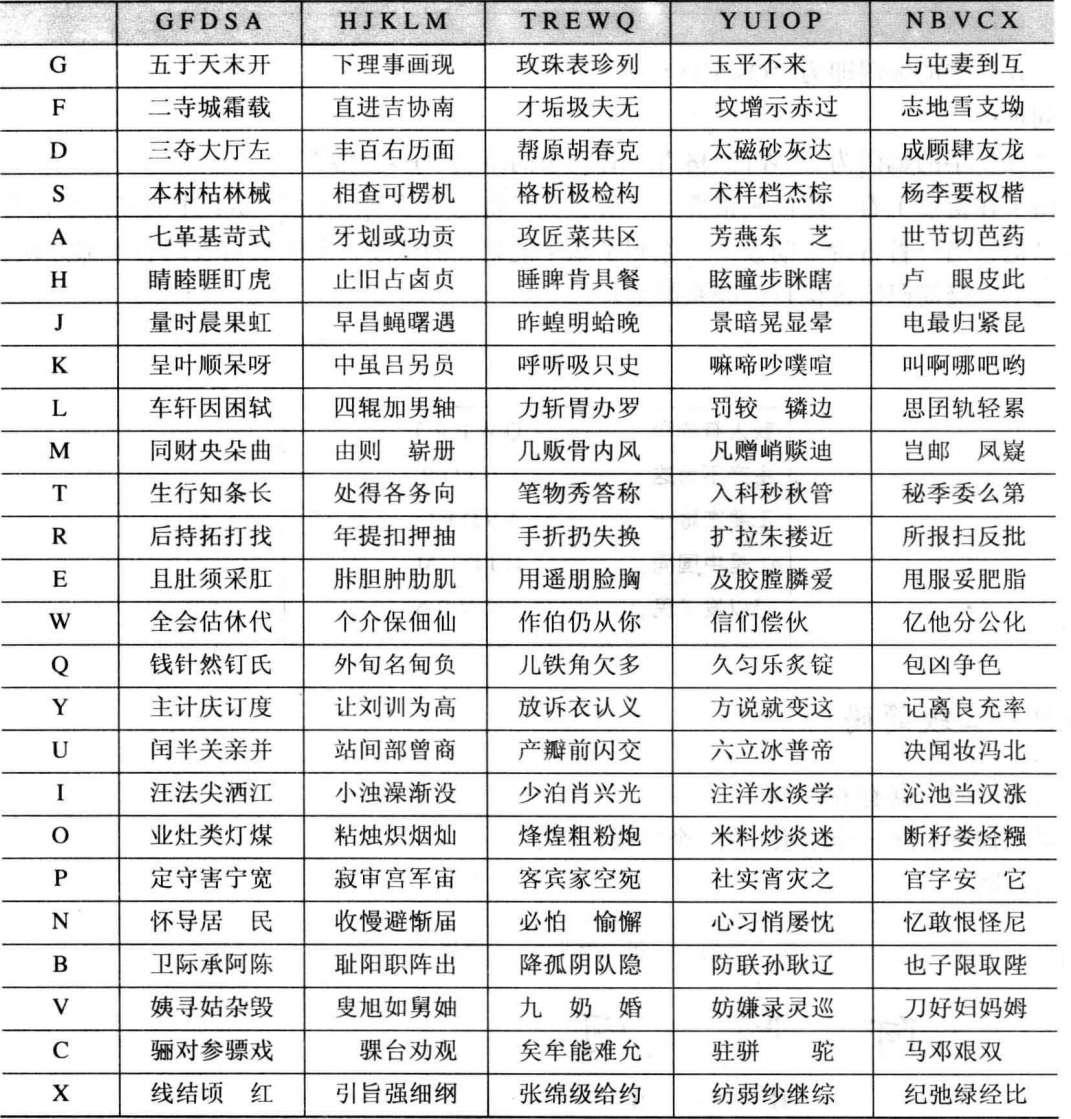
4.9.3 三级简码
三级简码一共有四千多个。录入规则:第一个字根+第二个字根+第三个字根+空格

“琳”字的编码即为“G+S+S+空格”。
4.10 词组的录入
五笔字型输入法中,可以输入一些常用词组以提高输入速度。这些词组又分为二字词组、三字词组及多字词组,所有的词组的编码一律为4码,下面将分别介绍它们的取码规则。
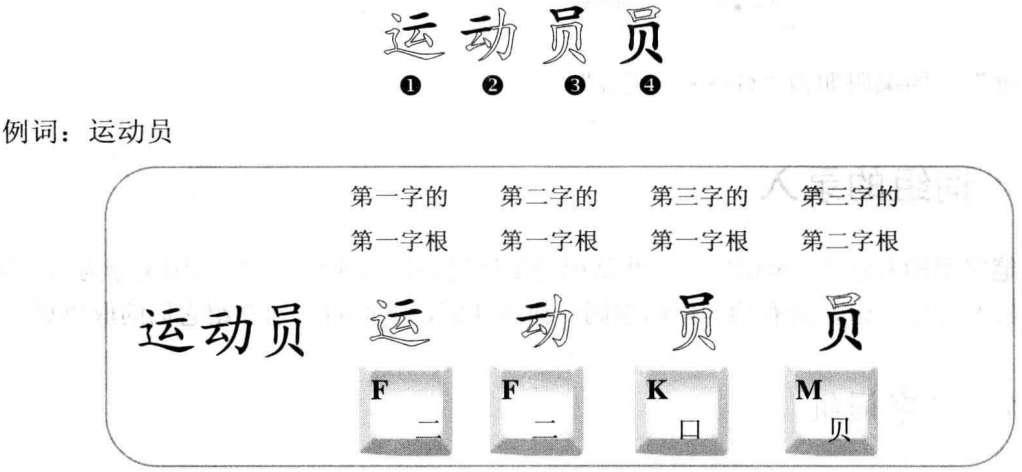
4.10.1 二字词组
二字词组指的是由两个汉字组成的词组。规则:分别取两个字的第一、二字根构成四位编码
小提示: (1)当词组中的汉字有一个或几个是成字根时,对于相应字的取码应按照成字根的规则来进行。如“方法”的编码为“YYIF”。 (2)当词组中的汉字有一个或几个是键名汉字时,对于相应的取码按照键名字的规则来进行。如“明白”的编码为“JERR”
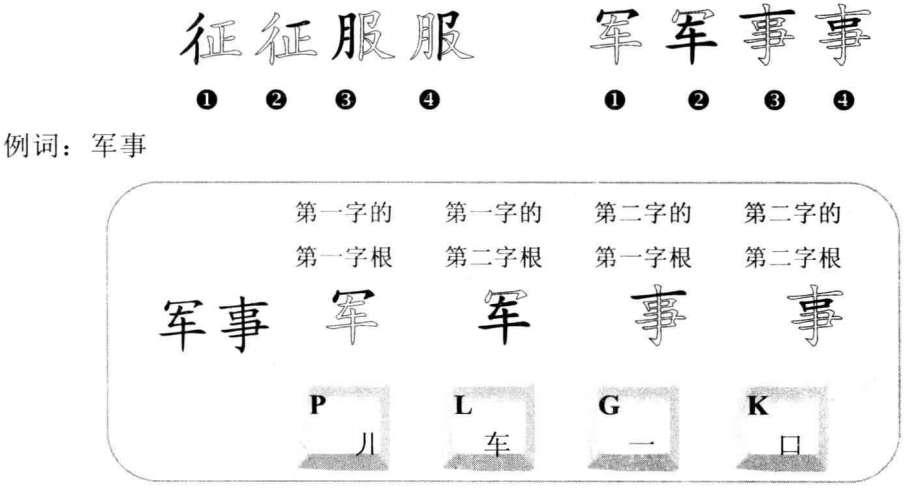
4.10.2 三字词组
三字词组指由3个汉字构成的词组。规则:第一个汉字第一个字根、第二个汉字的第一个字根、第三个汉字的第一个字根、第三个汉字的第二个字根构成四码。
我们在录入三字词组的时候,应该特别注意词组中的第三个字。因为我们要取它的第一、二个字根来构成编码。而前面的第一、第二个汉字,我们只取它们的第一个字根来构成编码。
4.10.3 四字词组
四字词组指的是刚好由四个字组成的词组。规则:分别取四个字的第一个字根构成四码。

总之,四字词组的取码规则就是将词组中的每一个汉字的第一个字根取出来构成四码。四字词组的录入方法是词组录入中最简单的一种,但是却是应用得比较广泛的录入方式。
五 总结
本文深入浅出地介绍了五笔输入法的原理与技巧,通过详细解析字根分布、编码规则及快速记忆方法,使读者能迅速上手并提升打字速度。它不仅适合初学者从零开始系统学习,也是进阶用户优化输入效率、突破速度瓶颈的理想选择。
此外,为加速学习进程,推荐搭配使用“巧手打字通”软件。该软件提供丰富的打字练习模块,从基础键位到实战文章,循序渐进,让学习过程更加生动有趣。通过实时统计与分析,精准定位薄弱环节,助力用户快速成为五笔打字高手。立即体验“巧手打字通”,让五笔学习之旅更加顺畅高效!