
一 中文输入法分类
中文的输入法根据输入特点大致可分为三类:音码、形码和音形码.
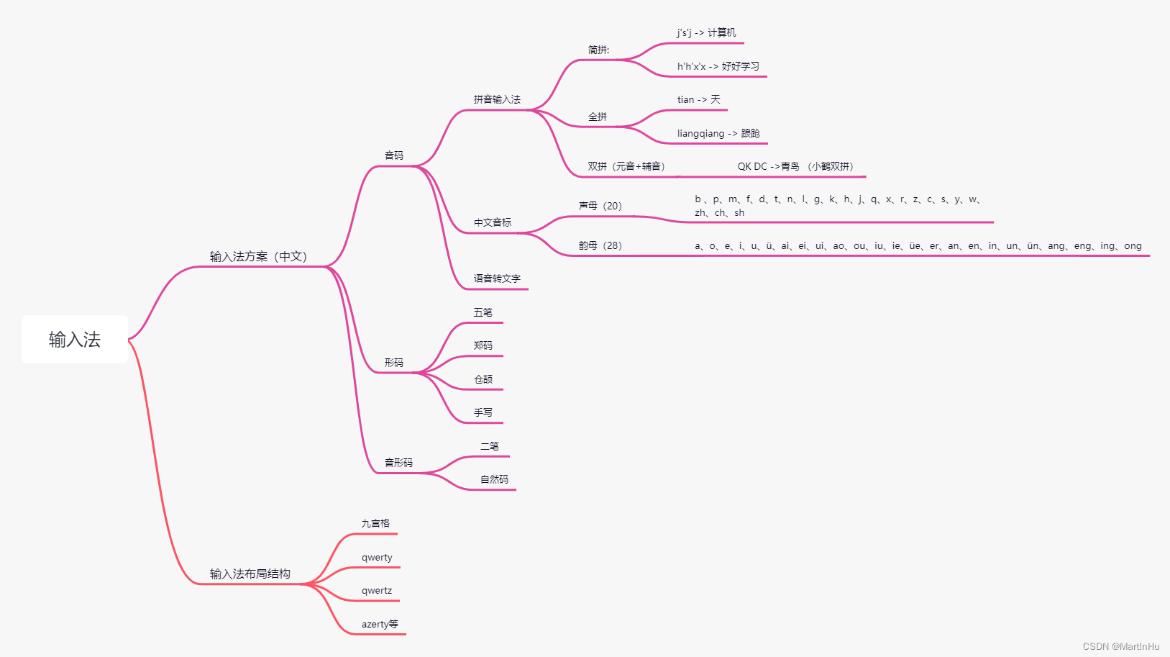
1.1 音码
根据汉字拼音设计的输入码,即拼音输入法。 常见的拼音输入法如下: 1. 简拼输入法:输入声母或声母的首字母来进行输入的一种方式。例如,我想输入“计算机”,则输入jsj

使用简拼输入,要求有强大的联想能力、丰富的词库。
全拼输入法:输入汉字的全部拼音,声母和韵母。例如,我想输入“计算机”,则需输入jisuanji
全拼提高了准确性,但增加的码长,牺牲了输入速度。
双拼输入法:对全拼的改进,将23个声母和24个韵母根据特定的组合分布在26键上,输入汉字的声母+韵母进行输入的一种方式。 以小鹤双拼为例(不同方案的双拼布局有所差异),当我想输入“青岛”,则仅需输入QK(qing)DC(dao)四个字母


1.2 形码
根据汉字的构造特点设计的输入法,常见的形码输入法如下: 1. 五笔输入法:完全依据笔画和字形特征对汉字进行编码的输入法,字根表如下:列如我想输入“湖北”,则需键入IED(湖)UX(北)。

- 郑码输入法:原理与五笔类似,字根表如下图: 例如,当我想输入“湖北”,则需键入VEJQ(湖)TIRR(北) 8个字母

- 仓颉输入法:最初只有繁体字版本,以字首做分类,字身做补充形成仓颉码:
- 理 - > — + 土 + 田 + 土 -> MGWG
- 哈 -> 口 + 人 + 一 + 口 ->ROMR

1.3 音形码
音形码是音码与形码的结合,即拼音+字根=字的输入方式,常见的音形码输入有: 1. 二笔输入法:又称二笔/两笔输入法,采用拼音首字母与笔画(两个笔画取一键)相结合的方式取码。 当想输入“武汉”时,需键入WH(武)HC(汉)


当然除了上述举例的输入法之外,还有其他许多的输入法,但基本实现原理与上述几种输入法一致。
二、输入法布局方式
当然关于输入法还有不同的布局方式,常见的有: - 九宫格 - qwerty - qwertz(德国) - azerty(法国)等。
就汉字输入法而言,除了上述按键输入,还有手写输入,语音转文字输入等方式,涉及到图形识别处理,语音识别处理更为复杂,暂且不展开介绍。 通过上述粗略介绍大致也能感受到输入法是一门复杂且灵活的设计艺术。输入法的设计和选择需要依据不同国家语言的构造特点,使用习惯,文化特点等个方面来设计,使之能够达到既快又准的目的。
三、输入法选择建议
3.1 依据使用场景选择
- 日常聊天与通用办公场景:如果您主要用于日常社交聊天、撰写普通文档等场景,音码类输入法是不错的选择。其中,全拼输入法上手难度极低,只要会拼音就能轻松输入,对于拼音基础扎实且对输入速度要求不是特别高的用户而言,是个稳妥的选择。而简拼输入法在熟练掌握后,配合强大的联想功能,能大幅提升输入效率,适合追求快速输入、不太在意偶尔选字操作的用户。双拼输入法虽然有一定学习成本,但一旦熟练,输入速度会有显著提升,对于长时间进行文字输入工作,如网文作者、编辑等人群较为适用。
- 专业文字处理场景:对于需要处理大量专业文档、对输入准确性和速度都有较高要求的专业人士,如律师、科研人员等,形码类输入法可能更合适。五笔输入法经过长期使用和优化,重码率低,输入速度快,在专业领域应用广泛。不过,其字根记忆难度较大,需要花费一定时间学习和练习。郑码输入法与五笔类似,在某些方面也有独特优势,使用者可根据自己的喜好和习惯选择。仓颉输入法在繁体中文输入方面有一定优势,适用于需要处理港澳台地区相关文档的用户。
- 特定行业场景:如果您从事特定行业,如医疗、金融、IT 等,行业专业词汇较多。此时,带有行业细胞词库的输入法能极大提高输入效率。一些音码输入法支持导入行业词库,在日常输入专业术语时,能快速准确地输出,减少选字时间。同时,部分音形码输入法也能通过独特的编码方式,兼顾输入速度和对专业词汇的支持,可根据行业特点和个人使用习惯进行挑选。
3.2 考虑个人能力与习惯
- 拼音基础与识字量:若您拼音基础扎实,识字量丰富,音码类输入法能很好地发挥您的优势。全拼和简拼可根据对速度和选字操作的接受程度选择。但如果您拼音不太准确,经常混淆一些音节,那么开启模糊音功能的拼音输入法或形码类输入法可能更适合您。形码输入法不依赖拼音,通过字形编码输入,能避免因拼音错误导致的输入困难。
- 学习能力与耐心:如果您学习能力较强,且有耐心去学习复杂的编码规则,那么形码类输入法如五笔、郑码等,经过一段时间的学习和练习,将为您带来高效的输入体验。而对于学习能力一般,希望能快速上手使用的用户,音码类输入法无疑是更好的选择,其简单易懂的输入方式能让您迅速开始高效输入。对于音形码输入法,它结合了音码和形码的特点,学习难度适中,也可根据自身学习能力和对输入方式的偏好来决定是否选择。
- 已有输入习惯:如果您之前一直使用某种输入法,已经形成了一定的输入习惯,除非有特殊需求,否则不建议轻易更换。例如,长期使用全拼输入法的用户,突然切换到五笔输入法,可能会面临较长时间的适应期,反而影响工作和学习效率。但如果您对当前输入法的某些方面不满意,如重码率高、词库不丰富等,可以尝试在同类输入法中寻找更优化的产品,或者根据自身需求尝试其他类型的输入法。
3.3 关注输入法特性
- 词库丰富度与更新速度:丰富且及时更新的词库能大大提高输入效率。在选择输入法时,要关注其词库是否包含大量常用词汇以及当下流行的网络用语、新出现的专业术语等。一些知名的输入法会定期更新词库,以适应语言的发展和用户的需求。同时,部分输入法支持用户自定义词库,方便用户添加个人常用词汇,进一步提升输入体验。
- 联想功能的智能程度:智能联想功能可以根据已输入的字词预测用户接下来可能要输入的内容,减少按键次数。好的联想功能不仅能准确预测常用词汇和语句,还能根据用户的输入习惯进行个性化联想。在试用输入法时,可以通过输入一些常见语句,观察其联想结果的准确性和实用性,以此来判断联想功能的优劣。
- 界面友好度与个性化设置:输入法的界面友好度也会影响使用体验。简洁明了、易于操作的界面能让用户快速找到所需功能。此外,个性化设置也是一个重要因素,如是否支持皮肤更换、按键音效设置、候选字字体大小和颜色调整等。这些个性化设置可以让用户根据自己的喜好和使用环境,打造最适合自己的输入法界面。
- 占用系统资源与稳定性:如果您的电脑或移动设备配置较低,那么输入法占用系统资源的情况就需要重点关注。占用资源过多可能会导致设备运行缓慢,影响其他程序的正常使用。同时,输入法的稳定性也至关重要,频繁出现卡顿、崩溃等问题会严重影响输入效率。在选择输入法时,可以查看其他用户的使用评价,了解其在不同设备上的资源占用和稳定性表现。